
Data mining social media aims to replace cold call insurance leads

[Editor's Note: This is the second in an ongoing, occasional series on the impact of big data on the insurance industry. Read the first series installment here.]
A new bride-to-be tweets about the joys, and anxieties, of her future life as a married woman.
That is followed by a polite Twitter message of congratulations from a friend of a friend who casually notes that he is an insurance agent. Fast forward a few months and the woman recalls her Twitter friend – the insurance agent – when discussing family financial protection with her new husband.
This is the scene Northwestern Mutual imagined when it signed on to a partnership with Socialeads in 2018.
AI that 'reads public social media'
“We pitched an idea to build an artificial intelligence platform that reads public social media posts,” recalled Larry Hitchcock, co-founder and CEO, “then finds the ones that are ‘bought a new house,’ ‘got married,’ ‘had children,’ ‘moved across the country' – typical life events.
“The idea being that talking to somebody at the moment where these things are happening is going to be a little bit more fortuitous in building a relationship with them as a prospective policyholder.”

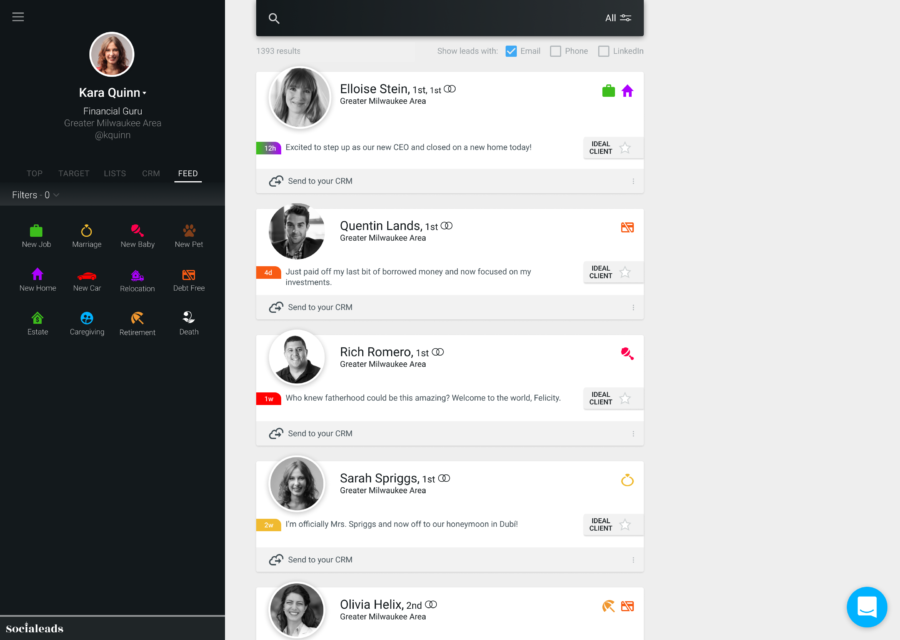
Four years later, Socialeads’ success is adding to the notion that “cold calls are dead.” That dreaded rite of passage for young agents in the insurance industry – the uncomfortable phone calls and endless rejection in search of a random viable lead – is fast becoming a relic of yesteryear.
Instead of cold calling, big data is helping startups like Socialeads target prospects, but with exceptional efficiency. In this case, Hitchcock explained how his company does it without, he maintains, invading privacy or resorting to unseemly use of personal information.
“If you tweeted something that was public, and one or more Northwestern Mutual advisors is following you on Twitter, that tweet would end up in our data,” he said. “We would only surface it to the NM customers or clients. None of the data in our world comes in that is marked private or protected.”
In many instances of big data mining, skepticism abounds. The insurance industry has a long and difficult history with statistics and data and critics say stronger regulation is needed to protect consumers.
‘Better customize the price’
Insurers have relied on data for as long as insurance has existed. Today’s insurers use myriad big data to underwrite more accurately, price risk and create incentives for risk reduction. In some instances, the carrot-stick approach is helping to encourage customers to share their personal data.
John Hancock rolled out its Vitality life insurance program for all policyholder in 2018. The insurer trades premium savings and rewards in exchange for exercising, eating well and getting regular medical checkups. Policyholders can earn an Apple Watch or receive a complimentary Fitbit device to make it easy to record their healthy activities.
Likewise, telematics allows insurers to collect real-time driver behavior and usage data to provide premium discounts and usage-based insurance.
“People don't realize to the extent it tracks how hard you brake, how hard you accelerate, the G forces on your turns, things like that,” noted Robert Clark, CEO of Cloverleaf Analytics, an insurance intelligence startup based in Austin, Texas. “So, they can better customize the price of the insurance. I think that financial incentive is helping drive that and create an acceptance of giving that information to an insurer.”
The thorny ethical issues arise when it comes to data consumers don’t consent to share with insurers – and might not even be aware is out there.
That’s where Socialeads found a comfortable middle ground. The very public nature of Twitter helps, after all, creating a profile and tweeting are voluntary public activities.
A spokeswoman for Northwestern Mutual declined comment for this story. But the insurer is committed to contacting only those who have made some social media connection to the industry, Hitchcock said.
“Northwestern Mutual doesn't want to know what everybody on Twitter is talking about. They want to know what potential customers are talking about who have some linkage to either their brand ."
— Larry Hitchcock, co-founder and CEO, Socialeads
“Northwestern Mutual doesn't want to know what everybody on Twitter is talking about,” Hitchcock said. “They want to know what potential customers are talking about who have some linkage to either their brand – meaning they might follow one or more their executives, they might follow their flagship Twitter account – or they might follow the advisor in the field in their hometown.
“So that there's a way that Northwestern Mutual can, through that social fabric, be connected to a prospective client and then reach out to them.”
Big data can discriminate
It’s the wild west-level big data usage that concerns Douglas Heller, director of insurance for the Consumer Federation of America. The CFA is a nonprofit research and advocacy organization that represents consumer interests in a variety of topical areas. Heller spends much of his time researching and testifying on insurance issues nationwide and calls big data a major concern.
“The insurance companies have not proved themselves capable or willing to look in the mirror with respect to bias and discrimination that comes out of their big data strategies,” he said. “They just haven't done it.”
There are numerous examples of how big data algorithms can discriminate against communities of color. For example, a 2017 study by Consumer Reports and ProPublica found disparities in auto insurance prices between minority and white neighborhoods that could not be explained by risk alone.
The study examined auto insurance premiums and payouts in California, Illinois, Texas and Missouri, and found that insurers were charging premiums that were on average 30% higher in ZIP codes where most residents are minorities than in whiter neighborhoods with similar accident costs.
Courts have consistently ruled that “redlining” based on race is illegal. Heller would like to see insurers follow through on the anti-racism stand the industry took after the May 2020 murder of George Floyd in Minneapolis. What that requires is a commitment, or regulatory oversight, to rigorously determine whether algorithms and other data-driven pricing models are truly discriminatory before they are used.
“The insurance executives said they want it to be different,” Heller said. “That requires action that is different.”
Unfortunately, there is a long history behind the lack of trust in insurance companies when it comes to data. In the 1880s, Prudential agents infamously carried around two rate books, one for whites and one for Blacks. The rates for Black people were sometimes as much as 30% higher.
To justify the changes, Prudential statistician Frederick L. Hoffman wrote a 329-page thesis claiming the genetic inferiority of the Black race supported discriminatory insurance rates. He had plenty of junk science to work with, the online magazine JSTOR Daily reported in a 2018 article.
Without a significant body of medical evidence available on Black health and mortality, researchers relied on Civil War records, state health reports, census statistics and comparative mortality records in large cities, said John S. Haller Jr., emeritus professor in the Southern Illinois University Department of History, in a 1970 journal article.
The generally accepted, and unproven, post-Civil War view, Haller wrote, was that slavery had been “extremely healthy” for Blacks. Also, it was thought that slaves “had been immune to tuberculosis, insanity, malaria, and tropical diseases,” he added. Further medical studies found that to be false, and also confirmed that Black freedmen were at a much higher mortality risk than they were as slaves.
Time and further studies have concluded that while Blacks indeed died at a higher rate from diseases such as cholera and pneumonia, the cause is attributable to poverty, racism, poor nutrition and working conditions, and lack of proper medical care.
Looking ahead
Traditionally, insurers move at a snail’s pace when it comes to new technologies such as artificial intelligence and the like. But the COVID-19 pandemic changed the game – insurers were forced to embrace technology to do business.
That acceleration is certain to influence the timeline for big data development projects. The race for business is never-ending and no big insurance company wants to be left behind, Clark said, who authored a January column declaring 2022 to be the insurance industry’s “big data moment.”
At the midpoint of the year, he is sticking with his predictions.
“I think social media, big tech, kind of put a pressure and expectations on insurance companies,” he said. “When you go shopping on Amazon, it's recommending things you like, and it kind of knows who you are. And I think customers began to feel like the insurance company really should know who I am and offer me products.”
InsuranceNewsNet Senior Editor John Hilton has covered business and other beats in more than 20 years of daily journalism. John may be reached at [email protected]. Follow him on Twitter @INNJohnH.
© Entire contents copyright 2022 by InsuranceNewsNet.com Inc. All rights reserved. No part of this article may be reprinted without the expressed written consent from InsuranceNewsNet.com.


How financial advisors can master social media and dramatically grow your practice
Proposed legislation would make family leave plans a type of insurance
Advisor News
- Dutch gambling tax hike falls short as prediction markets eye World Cup
- Caregiving: A challenge that costs employers billions
- Could your practice benefit from an advisory board?
- SEC nears settlement with accused scammer Tai Lopez
- The 3 things that shrink your Social Security income
More Advisor NewsAnnuity News
- Globe Life Inc. (NYSE: GL) Highlighted for Surprising Price Action
- Trademark Application for “EMPOWER YOUR MONEY” Filed by Empower Annuity Insurance Company of America: Empower Annuity Insurance Company of America
- Built-in guaranteed annuities: What advisors should know
- Malibu Life Holdings Completes Acquisition of TruSpire, Establishing Malibu USA and Accelerating Entry into the U.S. Retail Annuity Market
- Why job boards are failing insurance agencies
More Annuity NewsHealth/Employee Benefits News
- They Harvest the Nation's Food, but a New Rule May Strip Them of Health Insurance
- Colorado hospitals poised to receive $455 million Medicaid funding boost
- State Health Plan brings back Blue Cross NC, approves Novant and UNC Health deals
- Findings in Type 2 Diabetes Reported from Institute of Urban and Demographic Studies (Impact of Health Insurance Coverage on Diabetes Care Quality: A Systematic Review and Meta-analysis of Racial, Ethnic, and Gender Disparities in U.S. Adults …): Nutritional and Metabolic Diseases and Conditions – Type 2 Diabetes
- Nassau University Medical Center Researchers Provide New Study Findings on Health and Medicine (Health insurance payor type and care deviations in patients with trauma with lower extremity fractures): Health and Medicine
More Health/Employee Benefits NewsLife Insurance News
- Could your practice benefit from an advisory board?
- AM Best Revises Outlooks to Stable for Missouri Farm Bureau Group’s Members and Farm Bureau Life Insurance Company of Missouri
- Globe Life Inc. (NYSE: GL) Highlighted for Surprising Price Action
- AM Best Assigns Credit Ratings to China Ping An Insurance (Hong Kong) Company Limited
- Reliance Matrix Expands Employee Navigator Integration with New Evidence of Insurability (EOI) API Enhancement
More Life Insurance News